

python怎么保存(python怎么保存代码交作业)
python怎么保存(python怎么保存代码交作业)
一篇文章写清楚一个问题,关注我,自学python!
今天用一个实例给大家写写在机器学习中如何将训练好的模型储存起来方便下次调用。
模型储存的必要性
当我们训练好一个机器学习模型后,如果下次还想用这个模型,我们就需要把这个模型保存下来,尤其是在大数据中训练模型很耗时间的情况下,一定要保存模型,然后下次直接导入就好了,不然每次都跑一遍,训练时间短还好说,要是一次跑好几天的那种模型,不保存就会很悲催。
今天给大家介绍两种保存机器学习模型的方法:

一种就是使用python自带的pickle另一种使用sklearn中的模块joblib
pickle储存模型实际操练
首先我们看pickle怎么用,要储存的模型还是我上一篇文章训练好的多元线性回归模型,见python机器学习:多元线性回归模型实战,现在我们将模型储存起来,代码如下
import pickle
with open('reg_pickle','wb') as f:
pickle.dump(reg,f)导入pickle后,用写入模式打开一个reg_pickle文件,然后将我们的模型reg存入到f中。
运行代码就可以看到我们的工作目录中出现了一个新的文件,这个新文件就是我们储存的模型

pickle调用模型
调用模型代码如下:
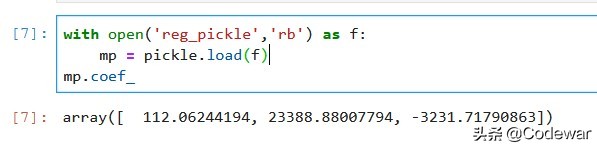
with open('reg_pickle','rb') as f:
mp = pickle.load(f)用只读模式打开我们刚刚储存的reg_pickle文件,然后用.load方法就可以载入模型再次使用啦
joblib储存模型
现在来看joblib的用法,要储存的模型还是我上一篇文章训练好的多元线性回归模型,见python机器学习:多元线性回归模型实战,现在我们将模型储存起来,代码如下:
from sklearn.externals import joblib joblib.dump(reg, 'reg_joblib')
首先载入joblib库,然后直接用.dump方法就可以实现对模型的储存,比第一种方法要简单得多。
运行代码就可以看见工作目录中出现了reg_joblib文件:

joblib调用模型
调用模型很简单,只需要用.load方法就行
mj = joblib.load('reg_joblib')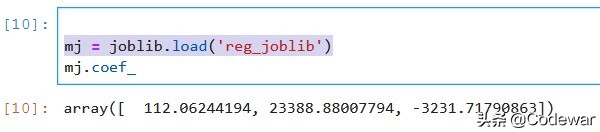
可以看到模型系数和原来模型一模一样。
小结
今天给大家介绍了两种储存机器学习模型的方法,相比pickle,我更加推荐大家使用joblib,因为更简洁,还有根据官方文档介绍joblib效率也更高。感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python的,加油。
(站外链接发不了,请关注后私信回复“数据链接”获取本头条号所有使用数据)
往期内容:
python机器学习:多元线性回归模型实战
python机器学习:如何划分训练集和测试集
-
- find用法(python爬虫find用法)
-
2024-02-02 01:10:56
-
- alt键怎么读(alt键怎么读英文)
-
2024-02-02 01:08:50
-
- 92号油价今天多少(92号汽油油价今天多少钱)
-
2024-02-02 01:06:43
-
- 美国谁发明了避雷针(美国谁发明了避雷针)
-
2024-02-02 01:04:36
-
- 汉族民歌体裁分为哪三类(汉族民歌体裁分为哪三类特点)
-
2024-02-02 01:02:29
-
- 苹果官网验机查询入口(苹果手机查询序列号 官网 真伪)
-
2024-02-01 09:43:04
-

- 马自达mx5论坛车友(马自达mx5 2021款)
-
2024-02-01 09:40:58
-
- 电脑启动黑屏不进系统无信号(电脑启动黑屏不进系统无信号怎么解决)
-
2024-02-01 09:38:52
-
- 电脑标点符号快捷大全双引号(标点符号双引号的正确用法)
-
2024-02-01 09:36:46
-
- saab汽车质量怎么样(saab是什么车贵吗)
-
2024-02-01 09:34:40
-
- cpuz测试分数天梯图移动端(8700kcpuz测试分数)
-
2024-02-01 09:32:34
-
- 优6网(北京优个网信息技术有限公司)
-
2024-02-01 09:30:28
-
- 手机cpu排行榜天梯图2021年
-
2024-02-01 09:28:22
-

- 苹果手机来电闪光灯怎么开(苹果手机来电闪光灯怎么开11 pro Max)
-
2024-02-01 09:26:16
-
- 苹果键盘怎么打平方2(苹果输入法平方米怎么打m2)
-
2024-02-01 09:24:11
-

- 微信的黑名单怎么解除黑名单(微信的黑名单在什么地方能找到)
-
2024-01-31 12:35:20
-

- 真实是什么意思(真实是什么意思网络用语)
-
2024-01-31 12:33:14
-

- 做梦梦见牙齿掉了(做梦梦见牙齿掉了流了好多血)
-
2024-01-31 12:31:08
-

- 戒指戴中指上代表什么含义(戒指戴中指上是什么意义)
-
2024-01-31 12:29:02
-

- 空洞骑士诺斯克(空洞骑士诺斯克第二个怎么开)
-
2024-01-31 12:26:56
 麦玲玲说大s面相(大s面相克夫还是旺夫)
麦玲玲说大s面相(大s面相克夫还是旺夫)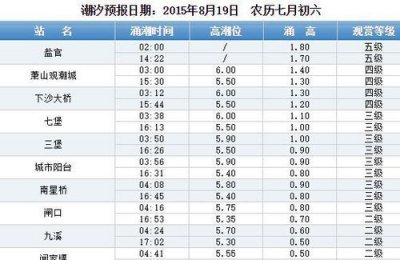 钱塘江潮水时间表,钱塘江潮水时间表是什么?
钱塘江潮水时间表,钱塘江潮水时间表是什么?